

Understanding Solana Data Streams and Protocols (Shreds, gRPC, WS, UDP)
Understanding Solana Data Streams and Protocols (Shreds, gRPC, WS, UDP)

When you think about making your Solana application or trading strategy faster, the first things to clarify are not the code or the server specs.
The starting point is two fundamental questions.
The starting point is two fundamental questions.
First, how far are you from the Solana validators you care about?
Which region does your application actually live in, and how many milliseconds does it take to reach a validator from there? This distance is the foundation of everything. If the distance is wrong, no amount of software or hardware optimization will unlock the performance that should be possible.
Which region does your application actually live in, and how many milliseconds does it take to reach a validator from there? This distance is the foundation of everything. If the distance is wrong, no amount of software or hardware optimization will unlock the performance that should be possible.
Second, where is the leader validator at any given time?
When Frankfurt is the leader, nodes near Frankfurt are structurally favored. When Tokyo is the leader, nodes near Tokyo are favored. Solana leaders rotate around the globe slot by slot. As long as this property exists, a single-region setup will always have time windows where it is physically disadvantaged.
When Frankfurt is the leader, nodes near Frankfurt are structurally favored. When Tokyo is the leader, nodes near Tokyo are favored. Solana leaders rotate around the globe slot by slot. As long as this property exists, a single-region setup will always have time windows where it is physically disadvantaged.
In practice, this means a realistic strategy must be multi-region.
By placing infrastructure in multiple locations such as Frankfurt, Amsterdam, New York, Chicago, Tokyo, and Singapore, you can observe the chain from a region that is close to the current or upcoming leader in every time band.
By placing infrastructure in multiple locations such as Frankfurt, Amsterdam, New York, Chicago, Tokyo, and Singapore, you can observe the chain from a region that is close to the current or upcoming leader in every time band.
With that physical and scheduling context established, we can talk about Solana’s data streams. In this article we focus on three that developers often encounter:
- WebSocket (WS)
- Geyser gRPC
- Shredstream (UDP Shreds)
We will look at what timing of data each one sees, what transport characteristics they have, and what they are actually good for.
The goal is not to pick something because “the name sounds fast,” but to understand how Solana itself works and how the underlying protocols behave, then connect that to app performance and UX in a concrete way.
The goal is not to pick something because “the name sounds fast,” but to understand how Solana itself works and how the underlying protocols behave, then connect that to app performance and UX in a concrete way.
Timing differences in how Solana data flows
The first step is to understand when, in Solana’s internal pipeline, different kinds of data actually appear.
Roughly speaking, there are three stages that are useful for reasoning about performance.
Roughly speaking, there are three stages that are useful for reasoning about performance.
The first stage is Shreds.
Validators exchange Shreds over UDP in order to build blocks. During this exchange, what flows over the network is data that has not yet been fully assembled into a block. If you can tap into this stage, you see changes on the chain at the earliest possible moment. The tradeoff is that, because this is UDP, you must assume packet loss and out-of-order arrivals and design your system accordingly.
Validators exchange Shreds over UDP in order to build blocks. During this exchange, what flows over the network is data that has not yet been fully assembled into a block. If you can tap into this stage, you see changes on the chain at the earliest possible moment. The tradeoff is that, because this is UDP, you must assume packet loss and out-of-order arrivals and design your system accordingly.
The second stage is Geyser gRPC.
After a validator has received Shreds and formed and confirmed a block, it can expose the results in a structured form via Geyser plugins. This is where Geyser gRPC streams come from: they emit events such as blocks, logs, and account updates. The timing is one step later than Shreds, but the data is already organized, making it much easier for applications to consume.
After a validator has received Shreds and formed and confirmed a block, it can expose the results in a structured form via Geyser plugins. This is where Geyser gRPC streams come from: they emit events such as blocks, logs, and account updates. The timing is one step later than Shreds, but the data is already organized, making it much easier for applications to consume.
The third stage is HTTP RPC and WebSocket.
Once data has gone through Geyser and other internal processing and has been written to the node’s internal stores, it becomes available through JSON-RPC and WebSocket notifications. Methods like getBalance, getProgramAccounts, and log subscriptions are all reading from this stored state. In terms of timing, this sits behind Geyser’s notifications and is the topmost “public API layer” that most applications see first.
Once data has gone through Geyser and other internal processing and has been written to the node’s internal stores, it becomes available through JSON-RPC and WebSocket notifications. Methods like getBalance, getProgramAccounts, and log subscriptions are all reading from this stored state. In terms of timing, this sits behind Geyser’s notifications and is the topmost “public API layer” that most applications see first.
Summarizing these three stages:
- Shreds are raw data very close to the moment of propagation.
- Geyser gRPC provides structured data at the point where blocks are confirmed.
- RPC / WebSocket expose stored data as APIs you query after the fact.
Which stage you observe determines how early you can detect changes on the chain. That timing difference alone already creates a significant performance gap.
Transport characteristics: UDP, gRPC, WebSocket, and TLS
Timing is one axis. The second axis is how the data is actually transported.
Shreds use UDP.
UDP has small headers and does not require connection setup. It does not provide retransmission or ordering guarantees, but in exchange it minimizes latency. For something like Shreds, where data is redundantly propagated between many validators, this simplicity and speed is exactly what you want.
UDP has small headers and does not require connection setup. It does not provide retransmission or ordering guarantees, but in exchange it minimizes latency. For something like Shreds, where data is redundantly propagated between many validators, this simplicity and speed is exactly what you want.
Geyser gRPC runs over TCP using a binary protocol.
Streaming RPC, header compression, and binary encoding allow it to move data more efficiently than typical HTTP+JSON. It is well suited for continuously consuming structured events in backends, monitoring systems, and analytics pipelines.
Streaming RPC, header compression, and binary encoding allow it to move data more efficiently than typical HTTP+JSON. It is well suited for continuously consuming structured events in backends, monitoring systems, and analytics pipelines.
WebSocket typically sits on top of TCP plus TLS, with JSON payloads.
The key advantage is that browsers and standard web stacks can use it directly, which is why it is everywhere in dApps and lightweight bots. The downside is that text JSON must be parsed, and headers plus encryption add overhead. Among the three, this tends to be the heaviest pattern.
The key advantage is that browsers and standard web stacks can use it directly, which is why it is everywhere in dApps and lightweight bots. The downside is that text JSON must be parsed, and headers plus encryption add overhead. Among the three, this tends to be the heaviest pattern.
On top of this, TLS itself adds another layer of cost.
When you use https, wss, or gRPC-TLS, every connection must perform a handshake and encrypt and decrypt payloads. For general web apps this is usually acceptable and not even noticed. For strategies where tens of milliseconds matter for UX or PnL, the overhead is noticeable.
When you use https, wss, or gRPC-TLS, every connection must perform a handshake and encrypt and decrypt payloads. For general web apps this is usually acceptable and not even noticed. For strategies where tens of milliseconds matter for UX or PnL, the overhead is noticeable.
The important point is that:
- The timing of when you see data (Shreds / Geyser / RPC)
- The way you transport it (UDP / gRPC / WebSocket / TLS)
are separate concerns, but both have a strong influence on your final latency and UX.
Putting speed in context: timing and transport
With those pieces in place, you can reason about speed more concretely.
From the viewpoint of timing:
- Shreds see the earliest stage.
- Geyser gRPC comes next.
- RPC / WebSocket come last.
From the viewpoint of transport:
- UDP is the lightest and fastest.
- gRPC over TCP is next, with efficient binary streaming.
- WebSocket with JSON and TLS is usually the heaviest.
If you normalize for “same region, same hardware, same network path,” the technical speed ordering is:
- UDP (Shreds)
- gRPC (Geyser)
- WebSocket (JSON-RPC notifications)
Of course, this is speed in isolation. In real systems you cannot look only at latency. You also have to consider reliability, correctness requirements, development cost, and how much complexity your team can actually absorb.
Reliability and development cost: why WS > gRPC > UDP in practice
In many real projects, the order in which data streams are adopted is almost the reverse of the technical speed ranking:
- First WebSocket
- Then Geyser gRPC
- Finally Shreds / UDP
This is not an accident.
Shreds (UDP) are the fastest but require you to design for missing and out-of-order data from the beginning.
You cannot assume every packet arrives and that all data is perfectly lined up. Your logic must handle gaps, reconcile with other streams if necessary, and tolerate noise. The payoff is minimum latency, but implementation and operations become meaningfully harder.
You cannot assume every packet arrives and that all data is perfectly lined up. Your logic must handle gaps, reconcile with other streams if necessary, and tolerate noise. The payoff is minimum latency, but implementation and operations become meaningfully harder.
Geyser gRPC gives you data that has already been confirmed and structured inside the node.
That makes it much easier to consume. Event-driven backends, alerting systems, on-chain analytics, and indexers can all build on Geyser with a good balance of speed, reliability, and implementation effort. For many teams, this is the natural second step once WebSocket-only setups hit their limits.
That makes it much easier to consume. Event-driven backends, alerting systems, on-chain analytics, and indexers can all build on Geyser with a good balance of speed, reliability, and implementation effort. For many teams, this is the natural second step once WebSocket-only setups hit their limits.
WebSocket’s main advantage is that it plugs directly into browsers and normal web infrastructure.
dApp frontends and lightweight services can use it with existing tools and libraries, and code samples are widely available. For shipping a first version of your product, WebSocket is often the most practical starting point, especially if you already solved the “distance to validators” problem.
dApp frontends and lightweight services can use it with existing tools and libraries, and code samples are widely available. For shipping a first version of your product, WebSocket is often the most practical starting point, especially if you already solved the “distance to validators” problem.
So in theory, the speed ordering is UDP > gRPC > WS.
In practice, the adoption ordering is usually WS > gRPC > UDP.
You need to keep both axes in mind and choose based on your current phase and goals instead of chasing an abstract “fastest” label.
In practice, the adoption ordering is usually WS > gRPC > UDP.
You need to keep both axes in mind and choose based on your current phase and goals instead of chasing an abstract “fastest” label.
How Shreds and Geyser gRPC work together
Once you go beyond basic speed tuning and start caring about every tens of milliseconds, the key question becomes how to combine Shreds and Geyser gRPC.
Shreds are for being the first to notice.
If you can receive Shreds close to the current leader, you can detect changes on the chain tens to hundreds of milliseconds earlier than someone watching only Geyser or RPC. For strategies where that gap translates directly into PnL, this matters a lot. The tradeoff is that you accept noise and design for it.
If you can receive Shreds close to the current leader, you can detect changes on the chain tens to hundreds of milliseconds earlier than someone watching only Geyser or RPC. For strategies where that gap translates directly into PnL, this matters a lot. The tradeoff is that you accept noise and design for it.
Geyser gRPC is for confirming and reasoning correctly.
At block confirmation time, Geyser emits logs, account changes, and other structured events. You can plug these into your strategy logic, risk controls, indexers, and monitoring systems. It is slower than Shreds, but the data is consistent and much easier to reason about.
At block confirmation time, Geyser emits logs, account changes, and other structured events. You can plug these into your strategy logic, risk controls, indexers, and monitoring systems. It is slower than Shreds, but the data is consistent and much easier to reason about.
A common pattern in the field is:
- Use Shreds to detect opportunities and assemble candidate transactions as quickly as possible.
- Use Geyser gRPC concurrently to verify blocks and logs and to drive your main logic and monitoring.
This separation lets you push latency while keeping your decision-making grounded in data that is stable and verifiable.
TLS, shared endpoints, and dedicated nodes
So far we have assumed the underlying node and network are the same. In reality, there is another massive structural difference: whether you are using a shared endpoint or a dedicated node.
A shared endpoint is used by many tenants at once.
It is exposed over the public internet, and traffic goes through a security perimeter. Encryption is mandatory; you cannot simply turn TLS off. The cost of encryption, decryption, and handshakes is perfectly acceptable for normal dApp usage but does show up if you are trying to shave off every possible millisecond in an HFT-style context.
It is exposed over the public internet, and traffic goes through a security perimeter. Encryption is mandatory; you cannot simply turn TLS off. The cost of encryption, decryption, and handshakes is perfectly acceptable for normal dApp usage but does show up if you are trying to shave off every possible millisecond in an HFT-style context.
A dedicated node is reserved for a single tenant.
Because you can restrict access by IP address and isolate the environment, you gain the option to disable TLS and use plain HTTP or plaintext gRPC. You also do not share CPU, memory, disk I/O, or network bandwidth with other customers, so your latency does not jump around because someone else is running a heavy workload on the same machine.
Because you can restrict access by IP address and isolate the environment, you gain the option to disable TLS and use plain HTTP or plaintext gRPC. You also do not share CPU, memory, disk I/O, or network bandwidth with other customers, so your latency does not jump around because someone else is running a heavy workload on the same machine.
If you run your Shreds, Geyser gRPC, and RPC all on dedicated nodes, all of these streams operate in an environment that is isolated from other tenants and from TLS overhead.
This combination is what makes dedicated setups reach latency ranges that shared endpoints, by design, cannot reach even with the same hardware.
This combination is what makes dedicated setups reach latency ranges that shared endpoints, by design, cannot reach even with the same hardware.
Shared nodes exist to provide solid performance for many users.
Dedicated nodes exist to push the limits when you really need the fastest possible path.
Dedicated nodes exist to push the limits when you really need the fastest possible path.
Multi-region and dedicated Shreds (UDP forwarding)
Going back to distance and leader position, as long as Solana’s leaders rotate around the globe, a single-region setup can never be the fastest everywhere, all the time.
This is where multi-region Shreds setups come in.
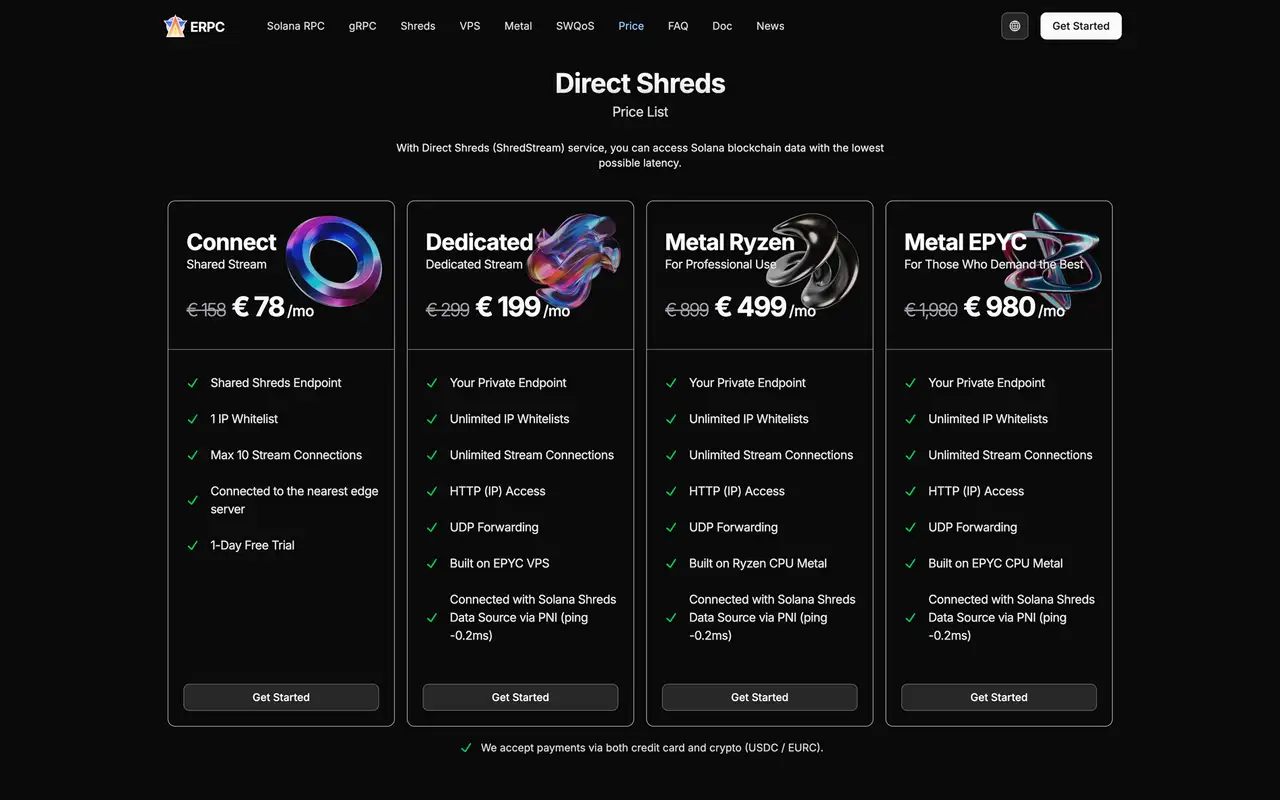
Dedicated Shreds (Premium Shreds, Standard Shreds, Metal Shreds, Limited Editions, and similar lines) combine:
- UDP delivery of Shreds as fast as possible
- Dedicated servers with minimal jitter
By deploying dedicated Shreds in multiple regions such as Frankfurt, Amsterdam, New York, Chicago, Tokyo, and Singapore, you can receive Shreds close to the leader, regardless of which region is currently favored.

A common pattern is to subscribe to multiple Shreds feeds from different regions at the same time and only act on the one that arrives first.
This reduces the impact of long-haul latency and regional congestion and allows you to approximate “always close to the leader” in a practical way.
This reduces the impact of long-haul latency and regional congestion and allows you to approximate “always close to the leader” in a practical way.
To make multi-region dedicated Shreds more accessible, ERPC provides discount coupons for multi-region usage:
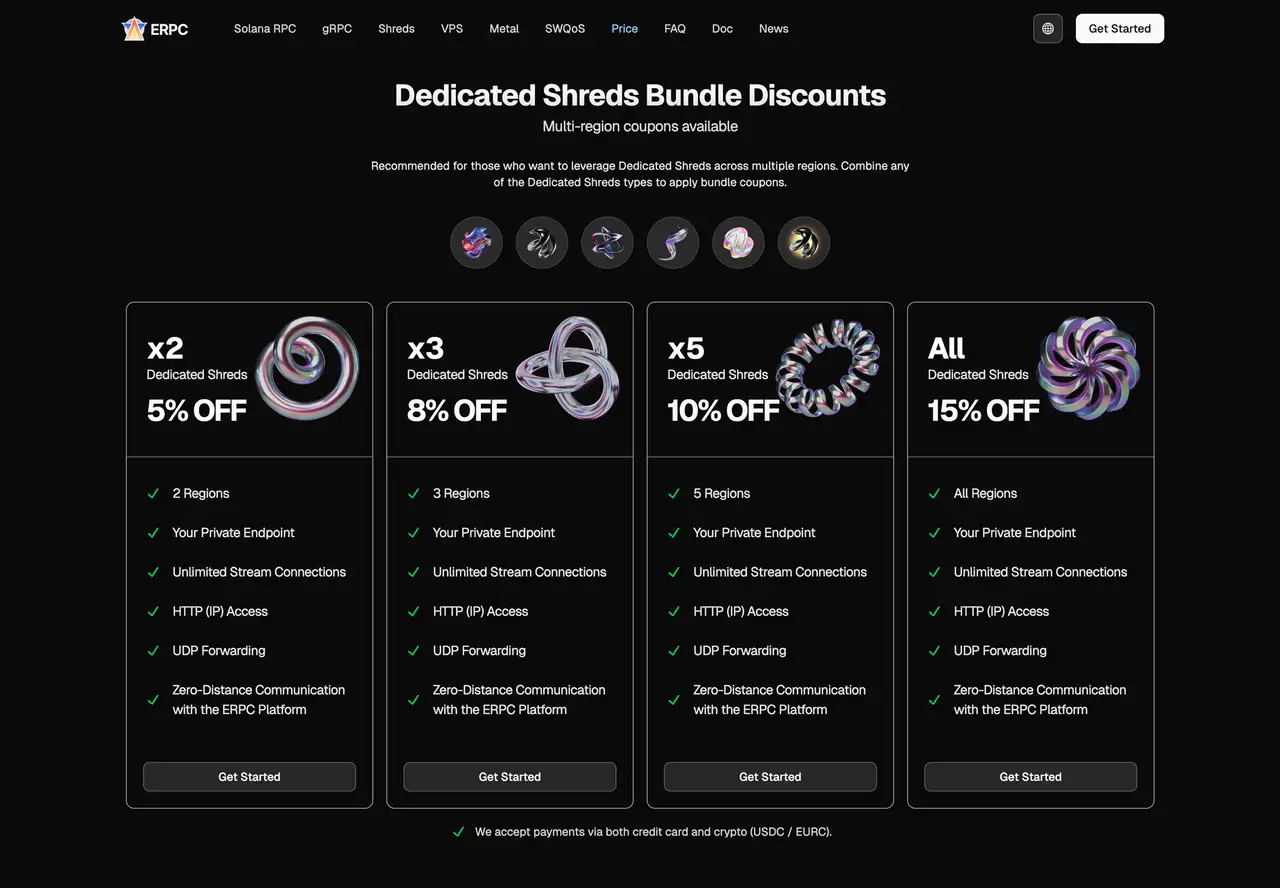
- 2 regions: 5% off
- 3 regions: 8% off
- 5 regions: 10% off
- All regions: 15% off
This makes it easier to design setups where you put the most premium Shreds tiers (for example, Premium or Metal) in the most competitive regions, and use more cost-efficient options in supporting regions, while still achieving broad coverage.
Shared Shredstream Bundles: a wider on-ramp into Shreds
Before you commit to fully dedicated Shreds everywhere, a multi-region Shared Shredstream setup can be a very practical intermediate step.
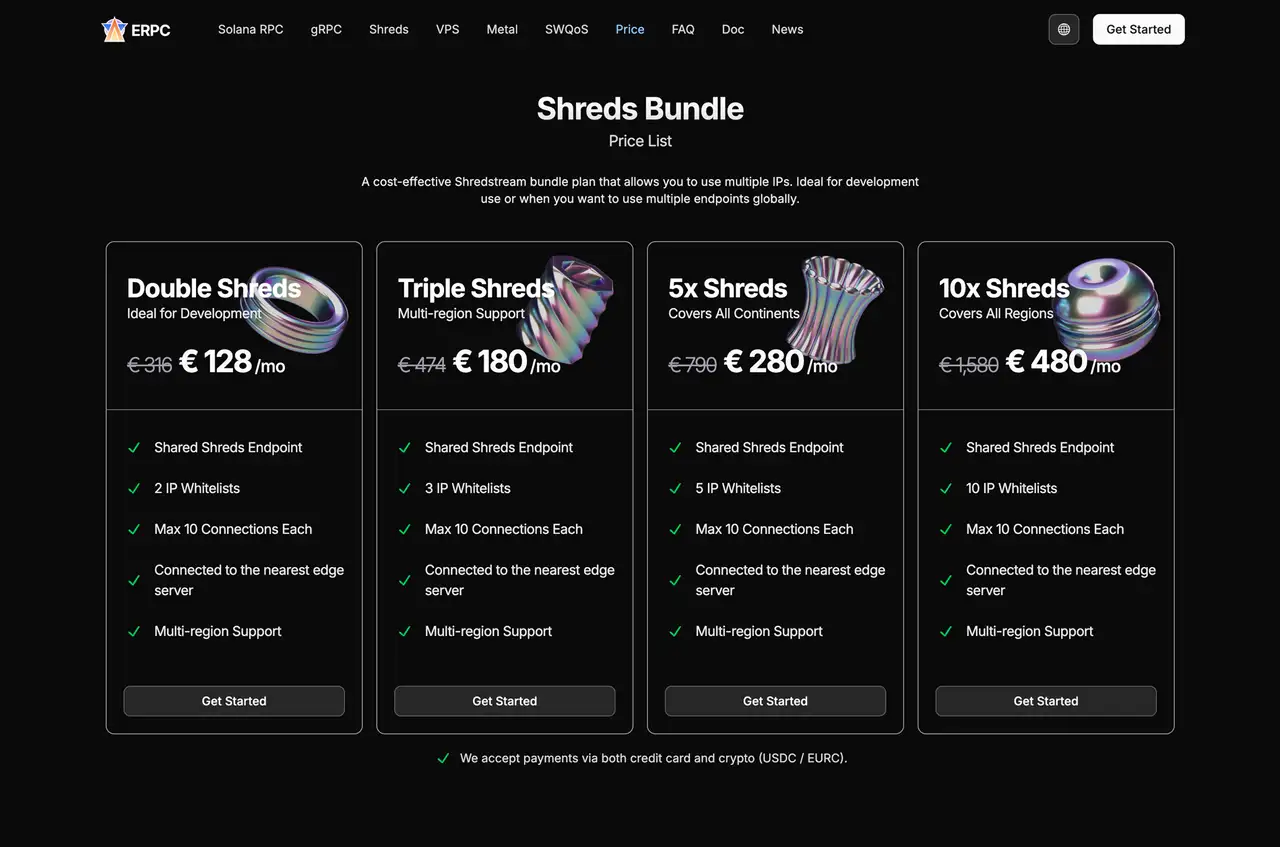
Shared Shredstream Bundles let you consume shared Shreds from multiple regions under a single plan.
Internally, Shared Shredstream takes data from the Shreds layer (UDP) and delivers it to you via gRPC. The source is still Shreds, so you see information one step earlier than Geyser gRPC, while benefiting from the convenience of gRPC streaming.
Internally, Shared Shredstream takes data from the Shreds layer (UDP) and delivers it to you via gRPC. The source is still Shreds, so you see information one step earlier than Geyser gRPC, while benefiting from the convenience of gRPC streaming.
In terms of how the layers line up:
- Dedicated Shreds via UDP forwarding are the very fastest, closest to propagation.
- Shared Shredstream is a gRPC stream derived from Shreds, sitting just above that.
- Geyser gRPC comes after that, at block confirmation timing.
Shared Shredstream Bundles include IP whitelisting, 10 connections, and automatic routing to the nearest edge. This keeps costs reasonable while allowing you to use Shreds-derived data simultaneously across regions such as Asia, North America, and Europe.
Instead of jumping straight into dedicated Shreds in every region, you can:
- Start with a Shared Shredstream Bundle to get hands-on experience with Shreds-based data.
- Use the logs and performance data to understand where it makes the most difference.
- Migrate high-impact regions to dedicated Shreds once you have evidence and a clear business case.
Practical steps by development phase
Putting this all together, it is easier to think in terms of phases.
In phase 1, choose the right region and distance, then build your dApp or bot using RPC and WebSocket.
Getting the region and network placement right often yields large UX improvements even before touching Shreds or gRPC. For launching a product, WebSocket is a very rational choice, especially from the frontend.
Getting the region and network placement right often yields large UX improvements even before touching Shreds or gRPC. For launching a product, WebSocket is a very rational choice, especially from the frontend.
In phase 2, add Geyser gRPC to strengthen backends, monitoring, and analytics.
Geyser gRPC lets you consume block, log, and account events efficiently and build robust indexers, alerting systems, and external APIs on top of them. It strikes a good balance between speed, reliability, and development cost and is a natural “second step” for many teams.
Geyser gRPC lets you consume block, log, and account events efficiently and build robust indexers, alerting systems, and external APIs on top of them. It strikes a good balance between speed, reliability, and development cost and is a natural “second step” for many teams.
In phase 3, bring in Shreds and UDP forwarding, where the latency differences directly affect PnL or UX.
By deploying dedicated Shreds in multiple regions and using multi-region discounts, you can enter the latency band required for HFT, MEV, and 0-slot strategies without designing everything from scratch in one shot.
By deploying dedicated Shreds in multiple regions and using multi-region discounts, you can enter the latency band required for HFT, MEV, and 0-slot strategies without designing everything from scratch in one shot.
The key point is not “UDP is theoretically fastest, so use only UDP everywhere.”
The key is to look at your phase and your economics, then decide where and when investing in Shreds and dedicated infrastructure actually moves the needle.
The key is to look at your phase and your economics, then decide where and when investing in Shreds and dedicated infrastructure actually moves the needle.
Using ERPC Bundles and VPS as a foundation
The ERPC Bundle plans are designed to give you a complete foundation:
- RPC (HTTP / WebSocket)
- Geyser gRPC
- Shared Shredstream gRPC
all under a single structure.

You can continue to use RPC and WebSocket as your main production interface, while experimenting with Geyser gRPC and Shredstream on the same network.
Because everything runs on a unified infrastructure, you can compare behavior and performance directly and make decisions based on actual measurements rather than assumptions.
Because everything runs on a unified infrastructure, you can compare behavior and performance directly and make decisions based on actual measurements rather than assumptions.
On top of that, you can combine this with VPS lines that live inside the same ERPC network, such as EPYC VPS and Premium Ryzen VPS.
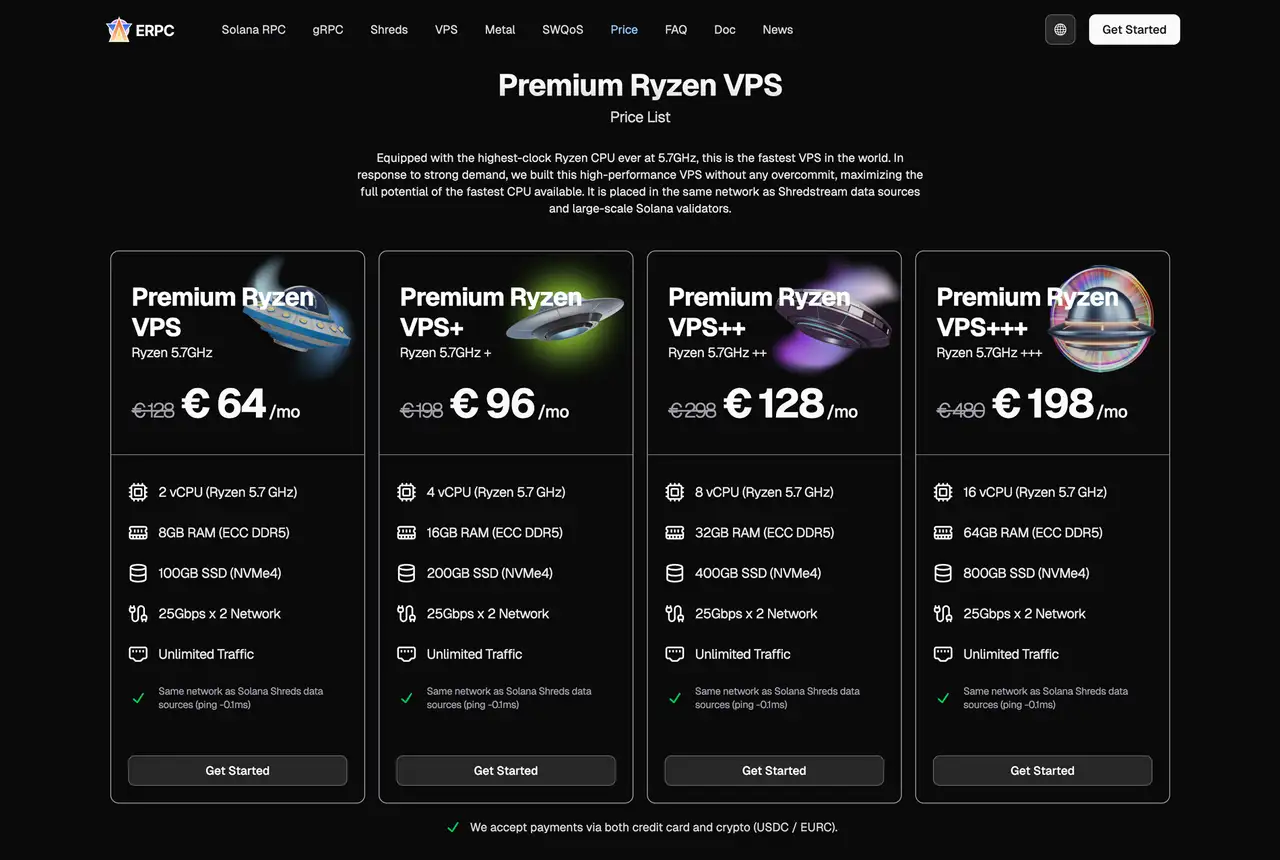
This lets you tune, in one place:
- Distance to Solana validators
- Choice of data streams (WS, gRPC, Shreds)
- Hardware performance
A practical approach is to first secure the right regions and ERPC Bundle + VPS foundation, then turn on faster layers (Geyser, Shared Shreds, dedicated Shreds) as your needs and economics evolve.
Conclusion: designing Solana performance from timing, transport, and distance
The performance and UX of a Solana application come from a combination of factors:
- Where your servers are located
- How close you are to the leader in each time band
- At which timing you receive on-chain data
- Which transport and protocol you use
- How your application logic reacts on top of that
Distance and leader position form the base. On top of that you have:
- Shreds for the earliest stage
- Geyser gRPC for confirmed, structured data
- RPC / WebSocket for accessing stored state via APIs
And on the transport side you have:
- UDP
- gRPC over TCP
- WebSocket over TCP with JSON and TLS
Choosing a stream or protocol by name or marketing alone is not enough.
The point is to select a structure that matches your use case along these three axes: timing, transport characteristics, and distance to the relevant validators.
The point is to select a structure that matches your use case along these three axes: timing, transport characteristics, and distance to the relevant validators.
ERPC and Validators DAO provide a Solana-focused network, RPC / gRPC / Shredstream services, VPS lines, and multi-region discounts for dedicated Shreds, so that you can build these structures at a realistic cost and evolve them as your needs grow.
If you would like to discuss data stream design, network distance optimization, or combinations of dedicated Shreds, Shared Shredstream Bundles, Bundles, and VPS, feel free to reach out via the Validators DAO Discord.
- ERPC: https://erpc.global/en
- SLV: https://slv.dev/en
- elSOL: https://elsol.app/en
- Epics DAO: https://epics.dev/en
- Validators DAO Discord: https://discord.gg/C7ZQSrCkYR
News


